|
Скрипт (сценарий) - это программа для взаимодействия клиента с сервером. Скрипты обычно пишут на языках Perl и PHP. В отличии от исходных текстов программ, написанных на языках Pascal или C, скрипты обычно интерпретируются, а не компилируются.
|
Давайте разберем подробнее скрипт, который мы использовали для проверки работы Perl:
#!/usr/bin/perl print "Content-type: text/html\n\n"; print "Perl работает!"; |
Обратим внимание на то, что каждая строка (кроме первой) должна заканчиваться точкой с запятой (;)
|
В заголовке каждого Perl-скрипта находится так называемая "hash-bang" (знак
решетки # и восклицательный знак !) строка:
#!/usr/bin/perl (без пробелов)
Если вы указали путь неправильно, Apache выдаст непонятное сообщение об ошибке, а в errors.log появится сообщение: "couldn't spawn child process". В этом случае проверьте первую строку в скрипте.
|
Попробуйте убрать из Perl-скрипта, предназначенного для вывода веб-страницы
на браузер, строку:
print "Content-type: text/html\n\n";
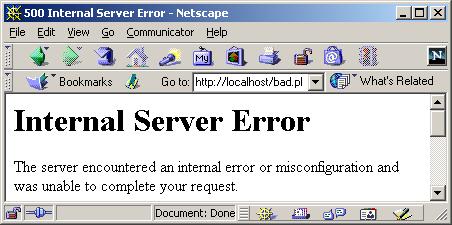
и вы сразу же увидите сообщение об ошибке - "Internal Server Error".
Почему Perl требует, чтобы эта строка предшествовала выводу информации на браузер? Попробуем разобраться, воспользовавшись бесплатной утилитой HttpRevealer. Эта небольшая программа для веб-разработчиков позволяет увидеть диалог между браузером и веб-сервером.
Установим эту программу и введем в браузер адрес сайта, например, http://dmoz.org/.
Как только вы нажмете "Enter", ваш браузер подключится к серверу (в данном случае, это dmoz.org.) и запросит главную страницу сайта. Получив запрос браузера, веб-сервер отвечает ему, возвращая главную страницу сайта. Просто, да?
Создается впечатление, что браузер и веб-сервер разговаривают друг с другом? Так и есть! Они говорят так же, как это делаем мы. Но разговаривают они не на человеческом языке, а на языке команд HTTP-протокола.
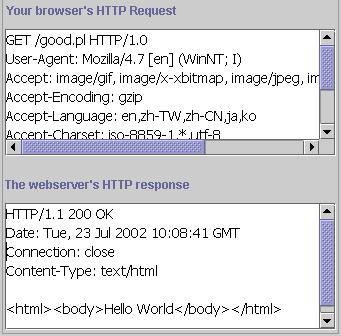
Давайте посмотрим, что они "говорят":
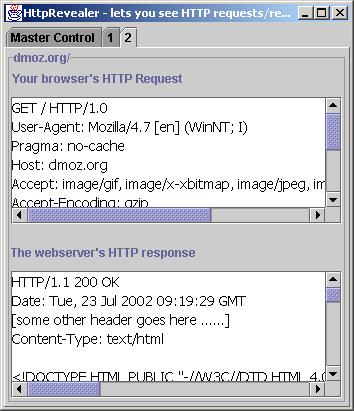
Выше приведен скриншот HttpRevealer. Верхняя панель отображает запрос браузера, а нижняя панель показывает ответ веб-сервера.
Не пугайтесь незнакомых слов. Сейчас мы все объясним. Если вы посмотрите на
первую строку HTTP-запроса в верхней панели, то увидите:
| GET / HTTP/1.0 |
Теперь, посмотрите, что отвечает веб-сервер:
| HTTP/1.1 200 OK ......... Content-Type: text/html <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> ...... |
Первая строка говорит: "Ok. Я нашел то, что вы ищете. Я тоже общаюсь по HTTP-протоколу версии 1.0" ... В третьей строке веб-сервер говорит: "Я готов предоставить вам HTML-документ. Получайте!". Следующий пустая строка означает конец заголовка. Пятая строка - это начало HTML-документа.
Вот так все просто! Но не стоит забывать, что мы смотрим этот диалог для того, чтобы выяснить, почему Perl требует наличия в скрипте строки "print Content-type", для того, чтобы он работал правильно.
Что произойдет, если мы упростим наш скрипт:
| #!/usr/pkg/bin/perl print "<html><body>Hello World</body></html>\n"; |
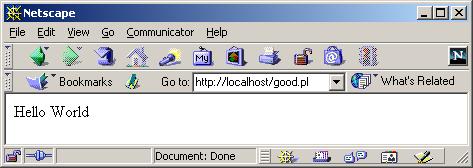
Чтобы устранить эту проблему, достаточно изменить Perl-скрипт, добавив в него строчку с указанием типа результата его работы:
| #!/usr/pkg/bin/perl print "Content-type: text/html\n\n"; print "<html><body>Hello World</body></html>\n"; |
Если ваш скрипт будет выводить не текстовую, а например, графическую информацию (допустим, изображение в формате jpeg), то содержимое данной строки изменится соответствующим образом: print "Content-type: image/jpeg\n\n";
В заключение, еще раз обратим внимание на то, что строка, указывающая тип выводимых скриптом данных, должна предшествовать собственно выводу полезной информации на браузер.
|
Третья строка нашего скрипта служит для вывода сообщения "Perl работает!":
print "Perl работает!";
print - это функция вывода. Ей передаётся один параметр - строка
в двойных (") или одинарных (') кавычках. Её можно записать и
так - print("Hello, World!\n"). Сочетание "\n" - это символ
перевода строки. Точнее это символ \ - говорящий интерпретатору,
что дальше идёт специальный символ, а не буква, и сам символ перевода строки
обозначающийся как n. Таких символов немало, например \t -
табуляция, \r - перевод каретки и т.д.
Компиляция - перевод машинной программы с языка программирования в машинные (двоичные) коды процессора.
Интерпретация - процесс непосредственного покомандного выполнения программы без
предварительной компиляции. В большинстве случаев интерпретация намного
медленнее работы уже скомпилированной программы, но не требует затрат на
компиляцию, что в случае небольших программ может повышать общую
производительность.
Вернуться к тексту Узнать подробнее ...
|
К содержанию
|
|
 |
Скачать новую версию данного учебника в одном архиве
Курс находится в процессе разработки, поэтому архив постоянно обновляется! |